Step 4: Transformer Layers (Attention)
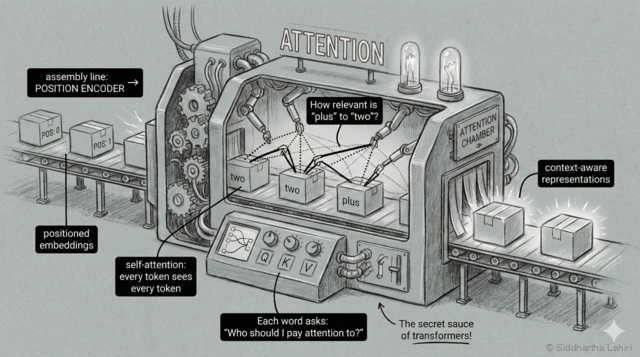
The fourth station is where the magic happens — a conference room where all the tokens meet and share information. This is the heart of the transformer.
Imagine you're reading a sentence and someone asks you what it means. You don't look at each word separately—you naturally consider how words relate to each other.
Right now, our model has three separate vectors for "two", "plus", and "three". But these vectors are like three people in separate rooms—they can't talk to each other. To solve "two plus three", the model needs to understand the relationship between these words.
This is what "attention" does. Think of it like a group discussion:

Imagine the words sitting in a meeting room:
"plus": Hey everyone, I'm an operation. Who am I working with?
"two": I'm a number! I'm sitting before you.
"three": I'm also a number! I'm sitting after you.
"plus": Got it—I need to ADD "two" and "three" together.How Attention Works: Query, Key, Value
Attention uses three concepts: Query, Key, and Value. Think of it like YouTube search:
- Query = Your search ("what am I looking for?")
- Key = Video titles ("what does this contain?")
- Value = Actual video content ("here's what you get")
"plus" creates a Query: "I need operands to add"
↓
It checks every token's Key:
- "two" Key: "I'm the number 2" ← high match!
- "plus" Key: "I'm an operator" ← low match
- "three" Key: "I'm the number 3" ← high match!
↓
"plus" retrieves their Values (actual information):
→ Now "plus" knows it's computing 2 + 3The model assigns an attention weight to each pair—a score from 0 to 1 indicating importance. When "plus" looks at other tokens, it assigns high weights (0.45) to "two" and "three", and low weights (0.10) to itself.
After this "discussion", each word's vector gets updated with information from the others:
| Word | Before attention | After attention |
|---|---|---|
| "two" | I'm the number 2 | I'm the number 2, AND I'm being added to something |
| "plus" | I'm an addition operation | I'm adding the number before me to the number after me |
| "three" | I'm the number 3 | I'm the number 3, AND I'm being added to something |
Multiple Heads: Different Perspectives
One attention mechanism learns one type of pattern. But language has many patterns. So we use multiple attention heads in parallel:
Single head might learn: "operations look at numbers"
But we also need:
- Head 1: Position patterns ("what comes before/after me?")
- Head 2: Semantic similarity ("which words mean similar things?")
- Head 3: Syntactic relationships ("subject-verb connections")
- Head 4: Different patterns we can't even name!
Our model uses 4 heads. GPT-4 uses ~96 heads.
Each head learns different patterns, then we combine them.The Complete Transformer Block
A transformer isn't just attention—each layer is actually a block with two parts:
┌─────────────────────────────────────────┐
│ TRANSFORMER BLOCK │
│ │
│ Input → [Multi-Head Attention] │
│ ↓ │
│ [Add & Normalize] ←── Residual │
│ ↓ │
│ [Feed-Forward NN] ←── NEW! │
│ ↓ │
│ [Add & Normalize] ←── Residual │
│ ↓ │
│ Output │
└─────────────────────────────────────────┘
Repeat this block 2-4 times (our model) or 96 times (GPT-4)What's the Feed-Forward Network? After tokens share information via attention, each token passes through a small neural network individually. This processes the blended information—attention shares info between tokens, feed-forward processes it within each token.
What are Residual Connections? The "Add" steps add the layer's input back to its output (output = input + processed). This creates "gradient highways" that help information and learning signals flow through deep networks.
The transformer repeats this block through multiple layers (we'll use 2). Each round refines the understanding:
- Layer 1: Basic relationships ("plus connects two numbers")
- Layer 2: Deeper understanding ("we're computing 2 + 3 = 5")
Here's a simplified view of how learning works:
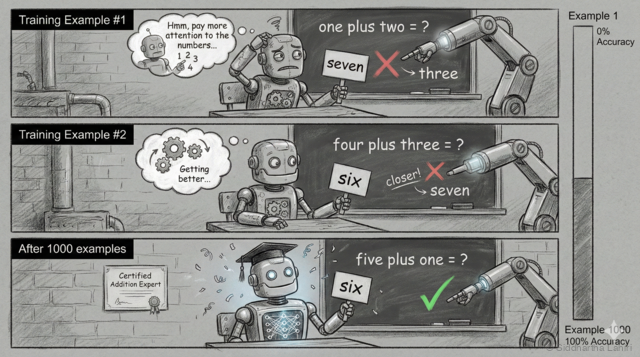
Training example #1:
Input: "one plus two" → Model guesses: "seven" (wrong!)
Correct answer: "three"
Model adjusts: "Hmm, I should pay more attention to 'one' and 'two' when I see 'plus'"
Training example #2:
Input: "four plus three" → Model guesses: "six" (closer!)
Correct answer: "seven"
Model adjusts: "I'm getting better at addition, but need more practice"
...after 1000 examples...
Training example #1000:
Input: "five plus one" → Model guesses: "six" (correct!)
Model has learned: when "plus" appears, add the numbers around itEach wrong answer nudges the model's internal numbers (weights) slightly. After thousands of nudges, the model has "learned" that 'plus' means addition—without us ever explicitly programming that rule.
It's like teaching a child math: you don't explain the neural pathways in their brain—you just show them "2 + 3 = 5" enough times, and their brain figures out the patterns.
Why Attention Matters for Long Contexts
Remember the context window from Step 3? Attention is what makes large context windows useful. Without attention, a model would process each word in isolation—it couldn't connect "she" in paragraph 10 to "Dr. Smith" in paragraph 1.
With attention, every word can "look at" every other word in the context window. In a 4,000-token input:
- Word 3,500 can attend to word 12
- The model can track characters, themes, and arguments across pages
- Context from the beginning influences predictions at the end
This is why transformers revolutionized language models—previous architectures (RNNs) struggled to connect information across long distances. Attention makes global understanding possible.
Masked Attention: No Peeking!
There's one important rule during generation: a token can only attend to tokens that came before it—not future tokens. Why?
During training, we show the model: "two plus three = five"
Without masking:
"plus" can peek ahead and see "five" → learns nothing!
It would just copy the answer.
With masking:
"plus" can only see "two" and itself
"three" can only see "two", "plus", and itself
The model must actually LEARN to predict.This is called causal masking or masked attention. It ensures the model learns to predict rather than cheat. During generation, this matches reality—future tokens don't exist yet!